
OLE 파일 포맷 (1) - 개요 및 기본 구조
OLE 파일(또는 COM Structured Storage1) 포맷은 MS 오피스인 워드, 엑셀, 파워포인트의 문서 포맷으로 사용되어 왔다. OLE 파일 포맷은 내부가 하나의 작은 하드 디스크와 같은 파일 시스템 구조를 가진다. 따라서 OLE 파일 내부에는 폴더 및 파일의 개념도 있다(정확히 표현한다면 스토리지(Storage)와 스트림(Stream)이다). 아래의 그림은 SSViewer(Structured Storage Viewer)2 프로그램을 통해 간단하게 MS 워드로 작성된 doc 파일의 내부 구조를 본 것이다.
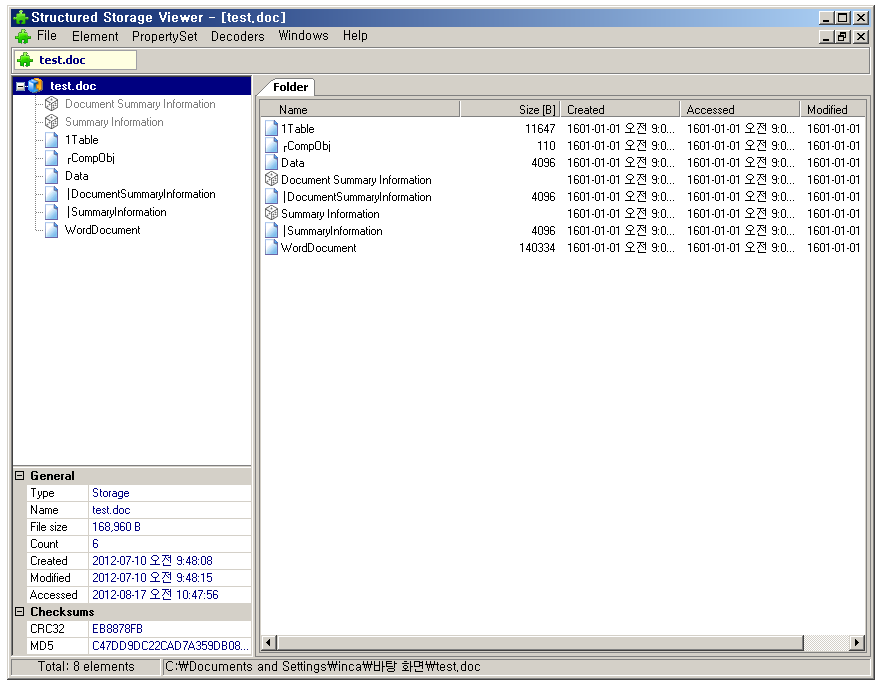
OLE 파일 내부가 하나의 작은 파일 시스템이다 보니 MS 오피스는 하위 호환성 및 상위 호환성(?)도 가진다. 예를 들면 MS 워드 2007 버전으로 문서를 작성해서 저장하더라도 MS 워드 2003 버전에서 해당 문서를 읽는 예가 그렇다. 이는 OLE 파일 내부에 MS 워드 2007 버전이 사용하는 스토리지/스트림과 MS 워드 2003 버전이 사용하는 스토리지/스트림을 각 각 만들어 두기만 하면 MS 워드 2003 버전은 해당 버전의 스토리지와 스트림만을 참조하면 된다. MS 워드 2007 관련 스토리지와 스트림이 존재한다 하더라도 해당 버전은 그 영역에 접근하지 않을테니 마치 상위 버전에서 작성된 문서를 하위 버전의 소프트웨어가 아무 문제없이 해당 문서를 읽어서 보여주는 것 같은 효과를 가지게 되는 것이다.
국내 워드프로세서들의 경우 자체 포맷을 고수하다가 결국 위에서 설명한 상/하위 문서 호환의 문제로 OLE 파일 포맷 구조로 바뀌었다.
사실 OLE 파일 포맷에 대해 본격적으로 이슈가 되었던 시기는 MS 오피스를 타깃으로 한 매크로 바이러스3가 등장한 1994 ~ 1995년 이었다. 당시 MS에서는 OLE 파일 내부 구조에 대해 공식적으로 발표하지 않았다. 그런 이유로 많은 해커들이 그 내부 구조에 대한 분석을 진행하게 되었고, 대표적인 프로젝트가 바로 LAOLA 프로젝트4이었다.
이제부터 설명할 OLE 파일 포맷은 상당히 많은 부분을 LAOLA 프로젝트의 문서를 기반으로 작업이 되었다. 그 이유는 당시 저자는 매크로 바이러스를 치료 할 수 있는 백신(Anti-Virus) 엔진을 개발하라는 임무가 주어졌고, OLE 파일 포맷에 대한 자료가 전무하던 시절이었기에 참조할 수 있는 문서라고는 LAOLA 프로젝트의 문서들뿐이었다.
하지만, LAOLA 프로젝트의 문서들은 대부분 과거의 자료이므로 당시에는 알 수 없었던 속성 값들이 지금은 추가적으로 많이 알려지기도 했다. 앞으로 다루게 될 Extra Big Block Allocation Table(XBBAT) Depot에 대한 부분은 LAOLA 프로젝트 문서에는 아예 존재하지 않는 내용들이다. 따라서 이제부터 설명할 OLE 파일 포맷은 최대한 최신의 정보를 담고 있다고 보면 된다.
OLE 파일의 구조
OLE 파일은 크게 2개의 블록으로 나뉜다. 바로 헤더 블록과 데이터 블록이다. 헤더 블록은 512byte 크기를 가지며, 데이터 블록은 512byte 이상을 가지게 된다.
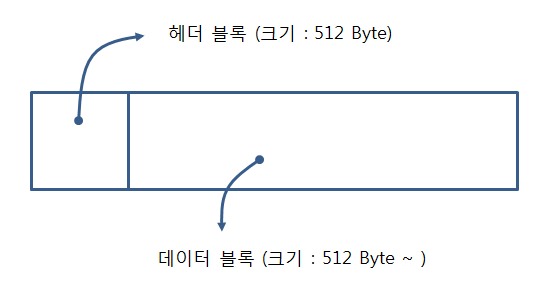
헤더 블록은 OLE 파일 전체의 주요 정보들을 가지고 있으며, 데이터 블록은 크게 아래의 정보들을 가지고 있다.
- 프로퍼티 (스토리지 및 스트림 정보를 보관)
- 스트림 데이터
- Big Block Allocation Table (BBAT)
- Small Block Allocation Table (SBAT)
이 중에서 데이터 블록의 대부분은 스트림 데이터가 차지하고 있다.
OLE 블록의 구조
OLE 헤더 블록은 OLE 파일의 주요 정보들을 담고 있는 블록이다. OLE 파일을 512byte 씩을 나누어 블록 번호를 부여한다. 이때 제일 첫 번째 블록은 -1 블록임을 기억해야 한다.
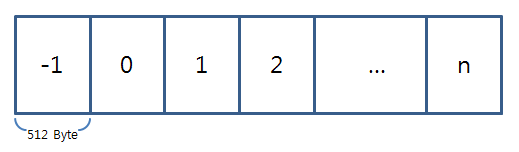
이때 -1 블록이 바로 헤더 블록이며, 0 .. n 블록이 데이터 블록이다. OLE 파일을 열어 512(0x200) Byte 만큼 읽으면 바로 헤더 블록을 읽은 것이 된다. 파이썬으로 다음과 같이 블록 번호를 주면 OLE 파일에서 해당 블록을 읽어주는 함수를 아래와 같이 작성할 수 있다.
[소스 코드 : ole.py]
001 : # -*- coding:utf-8 -*-
002 : # Module : ole.py
003 :
004 : #--------------------------------------
005 : # ReadBlock
006 : # OLE 파일에서 블록번호를 주면 해당 블록을 읽어 내용을 리턴한다.
007 : #--------------------------------------
008 : def ReadBlock ( fp, block_num ) :
009 : block_buf = ""
010 :
011 : # -1 블록의 위치가 0이며, 0 블록이 0x200 위치가 되도록
012 : # 아래의 공식을 사용한다.
013 : fp_pos = (block_num + 1 ) * 0x200
014 :
015 : try :
016 : fp.seek(fp_pos) # 계산된 위치로 이동한다.
017 : block_buf = fp.read(0x200) # 블록크기(0x200)만큼 읽는다.
018 : except :
019 : pass
020 :
021 : return block_buf # 읽은 내용을 리턴한다.
[소스 코드 설명]
- 11 ~ 13행 : 블록의 위치를 계산한다.
- 15 ~ 19행 : 계산된 블록의 위치로 이동하여 512 Byte를 읽는다.
우선 아래 예제는 ReadBlock 함수의 사용법을 보여주고 있다. 예제에서 사용된 파일은 아래아 한글 워드프로세서의 파일인 HWP 파일이다(HWP 파일 역시 OLE 파일 구조이다).
[소스 코드 : test_readblock.py]
001 : # -*- coding:utf-8 -*-
002 : # Module : test_readblock.py
003 :
004 : import ole
005 : import hexdump
006 :
007 : #-----------------------------------------------------------
008 : # Test 코드
009 : #-----------------------------------------------------------
010 :
011 : # -1 블록을 읽어 header에 저장한다.
012 : fp = open ( "test_ole.hwp", "rb" )
013 : header = ole.ReadBlock ( fp, -1 )
014 : fp.close()
015 :
016 : # header를 Hex 덤프 한다.
017 : hexdump.Buffer ( header, 0, 0x80)
[소스 코드 설명]
- 4 ~ 6행 : 필요한 모듈을 import 한다.
- 12 ~ 15행 : test_ole.hwp 파일을 열어 -1 블록을 읽어 들인다. 그리고 파일을 닫는다.
- 17행 : 읽어들인 -1 블록의 내용을 Hex 덤프한다. 물론 512 Byte를 읽기는 하였지만, 여기에서는 128(0x80) Byte만 출력한다.
위의 소스 코드를 실행하면 다음과 같은 결과를 볼 수 있다.
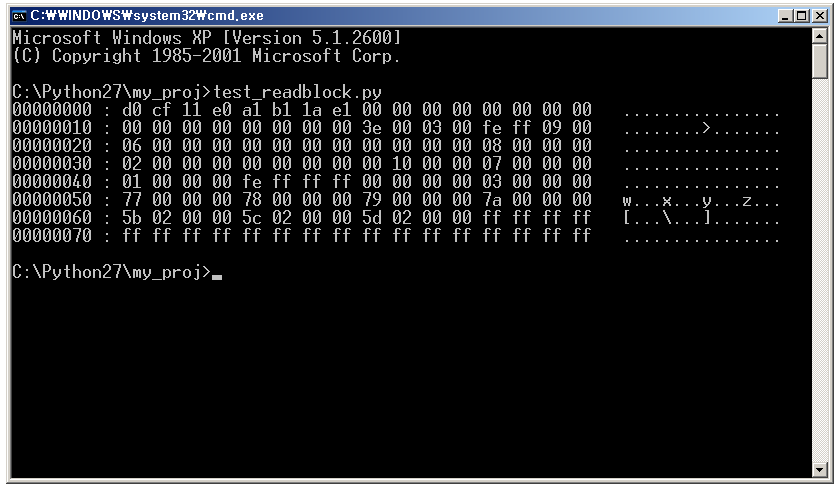
이제 OLE의 블록은 읽을 수 있게 되었으니 본격적으로 헤더 블록 및 데이터 블록의 구조를 살펴보기로 하자.
Update
- 2015-08-26 : 최초로 작성
-
COM Structured Storage : http://en.wikipedia.org/wiki/COM_Structured_Storage ↩
-
SSViewer(Structured Storage Viewer) : http://www.mitec.cz/ssv.html ↩
-
매크로 바이러스 : http://en.wikipedia.org/wiki/Macro_virus ↩
-
LAOLA 프로젝트 : http://stuff.mit.edu/afs/athena/astaff/project/mimeutils/share/laola ↩