
OLE 파일 포맷 (5) - Small Block Allocation Table(SBAT)와 SBAT Depot
OLE 파일의 데이터 블록의 대부분이 스트림 데이터로 채워져 있지만, 모든 스트림의 크기가 4096(0x1000) Byte를 넘는 것은 아니다. 즉, 작은 크기의 스트림도 많다는 의미이다. 스트림의 크기가 4096(0x1000) Byte 보다 크면 Big Block Allocation Table(BBAT)를 참조해서 링크 구조를 따라가서 블록을 취합하게 되는데 이때 한 블록의 크기는 512(0x200) Byte이다. 하지만, 스트림의 크기가 496(0x1000) Byte 보다 작다면 굳이 BBAT를 참조하여 512(0x200) Byte를 블록을 취합하는 것은 낭비이다. 따라서 OLE 파일에는 Small Block Allocation Table(SBAT)이 존재한다. 이때 SBAT를 참조하여 블록의 취합할 때에는 64(0x40) Byte 크기를 사용한다. 그런데 SBAT를 참조해서 취합된 블록 번호는 우리가 이미 알고 있는 블록 접근 방식이 아닌 새로운 블록 접근 방식을 사용하게 된다. 이는 아래에서 자세히 설명한다.
우선 헤더 블록의 60 위의 Start block of Small Block Allocation Table과 64 위치의 Number of Small Block Allocation Table Depot 값이 필요하다.
60 위의 Start block of Small Block Allocation Table의 값은 아래에서 보듯이 역워드로 전환한 값은 7이다. 즉, 7 블록부터 SBAT가 시작된다는 의미이다.

64 위치의 Number of Small Block Allocation Table Depot의 값은 아래에서 보듯이 역워드로 전환한 값은 1이다. 만약 1보다 크다면 이때는 BBAT에서 Entry를 추적해야 한다(즉, SBAT Depot은 BBAT 내에 존재한다는 의미이다). 그 블록을 취합하여 SBAT를 구성해야 한다.

아래의 그림은 SBAT를 추출하는 과정을 보여준다. 제일 먼저 Start block of Small Block Allocation Table의 값이 7을 확인하고 이후 BBAT Depot에서 Entry 7에 저장된 값을 확인한다. 그림에는 표시되어 있지 않지만, Number of Small Block Allocation Table Depot이 1인 것을 감안한다면 0xFFFFFFFE가 존재한다는 것을 알아차릴 수 있을 것이다. 만약 Number of Small Block Allocation Table Depot이 1보다 크다면 BBAT Depot의 Entry를 추적하여 모든 블록을 구해야 한다.
SBAT가 존재하는 블록들을 512(0x200) Byte를 읽어 취합하면 SBAT가 완성이 된다.
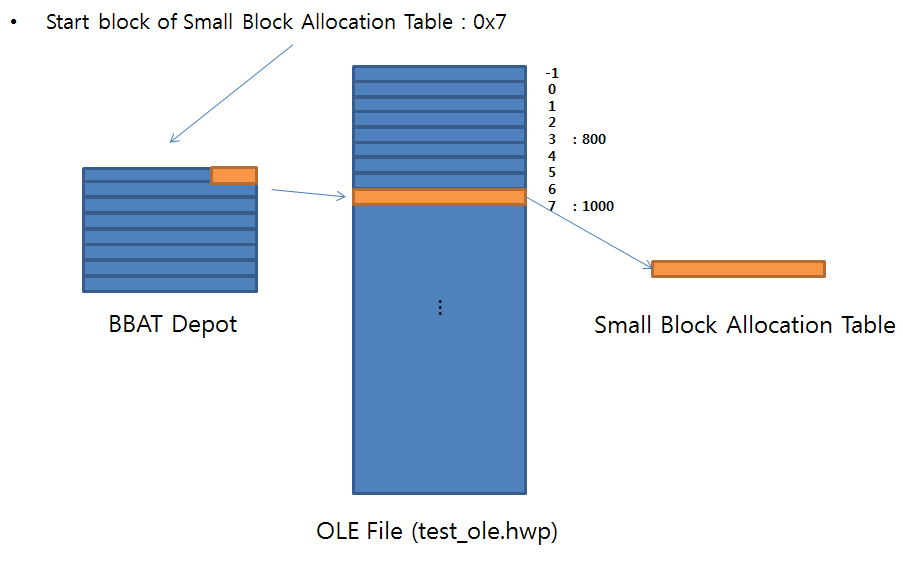
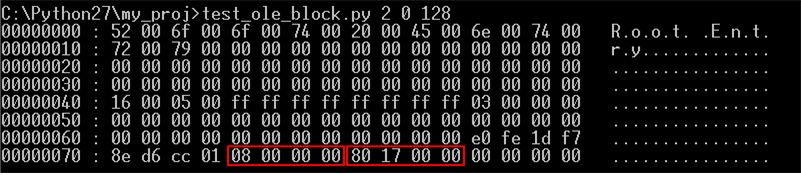
7 블록을 읽은 내용이 아래와 같다(원래 크기는 512Byte이다. 여기에서는 128 Byte만 읽어서 표시하였다).
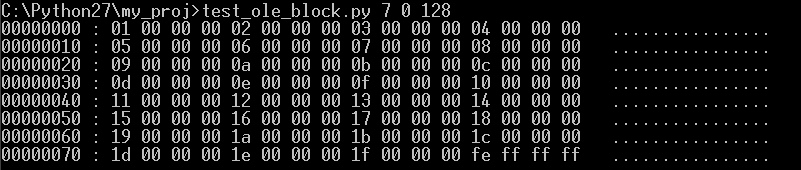
위 결과물에서 보는 것과 같이 구성은 BBAT와 다르지 않다. 역시 4Byte의 Entry 구조를 따르고 있다. test_ole.hwp의 FileHeader의 프로퍼티를 보면서 SBAT를 설명하기로 한다.
FileHeader 프로퍼티의 Starting block of Property는 0x4F(10진수로 79)이며, Size of Property는 0x100(10진수로 256)이다. 이 프로퍼티는 크기가 4096(0x1000) Byte보다 작기 때문에 BBAT가 아닌 SBAT를 참조하게 된다.
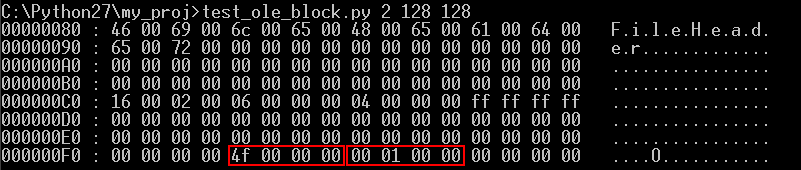
SSBAT는 7 블록에 존재한다고 앞에서 설명하였다. 따라서 7 블록에서 FileHeader 프로퍼티의 시작 위치인 0x4F(10진수로 79) Entry에 접근해보자. 한 개의 Entry는 4 Byte를 차지하므로 79 * 4 = 316이다. 따라서 아래와 같이 7 블록의 316 위치를 128 Byte 만큼 Hex 덤프 한 것이다.
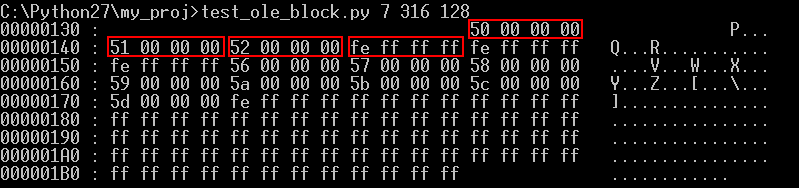
위의 결과를 통해서 FileHeader 프로퍼티가 차지하고 있는 Entry를 다음과 같이 구할 수 있다.
Entry 0x4F → Entry 0x50 → Entry 0x51 → Entry 0x52
이제 Entry를 알아냈기 때문에 해당 블록을 취합해야 하는데, 여기에서 또 다른 문제에 봉착했다. 그것은 바로 SBAT를 통해서 얻어낸 Entry들은 4.2.2절에서 설명한 OLE 블록의 구조와 전혀 별개의 블록이라는 점이다. 그렇다면 SBAT를 통해 얻어낸 블록들은 어디에 존재하는가?
바로 RootEntry가 그 정보를 보관하고 있다. 따라서 RootEntry 프로퍼티를 다시 살펴보도록 하자.
분명 RootEntry 프로퍼티는 그 동작이 스토리지와 동일하다고 생각하기 쉽다. 하지만, 위 결과물에서 보듯이 Starting block of Property와 Size of Property를 가지고 있다. 오히려 스트림처럼 보인다. RootEntry가 가진 데이터를 취합해보자.
- Starting block of Property : 8
- Size of Property : 0x1780
RootEntry에는 예외 규칙이 있다. 프로포티의 크기가 4096(0x100) Byte보다 크면 BBAT를 참조하고, 작으면 SBAT를 참조한다는 규칙을 따르지 않는다. 즉, RootEntry 프로퍼티는 프로퍼티의 크기와 상관 없이 무조건 BBAT를 참조한다.
RootEntry 프로퍼티의 시작 블럭인 8 블록을 시작으로 BBAT를 참조한다.
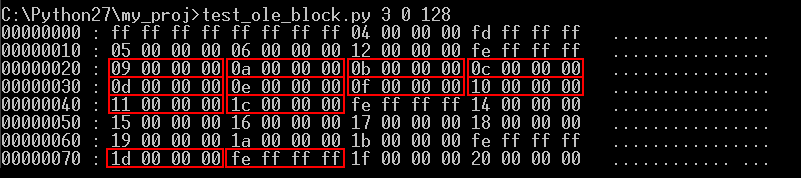
위 결과물에서 보는 바와 같이 BBAT를 참조하여 전체 Entry를 나열하면 다음과 같다.
Entry 0x8 → Entry 0x9 → Entry 0xA → Entry 0xB → Entry 0xC → Entry 0xD
→ Entry 0xE → Entry 0xF → Entry 0x10 → Entry 0x11 → Entry 0x1C → Entry 0x1D
따라서 해당 각 블록의 위치 정보를 표현하면 다음과 같다.
8블록(0x0x1200) → 9블록(0x1400) → 10블록(0x1600) → 11블록(0x1800)
→ 12블록(0x1A00) → 13블록(0x1C00) → 14블록(0x1E00) → 15블록(0x2000)
→ 16블록(0x2200) → 17블록(0x2400) → 28블록(0x3A00) → 29블록(0x3C00)
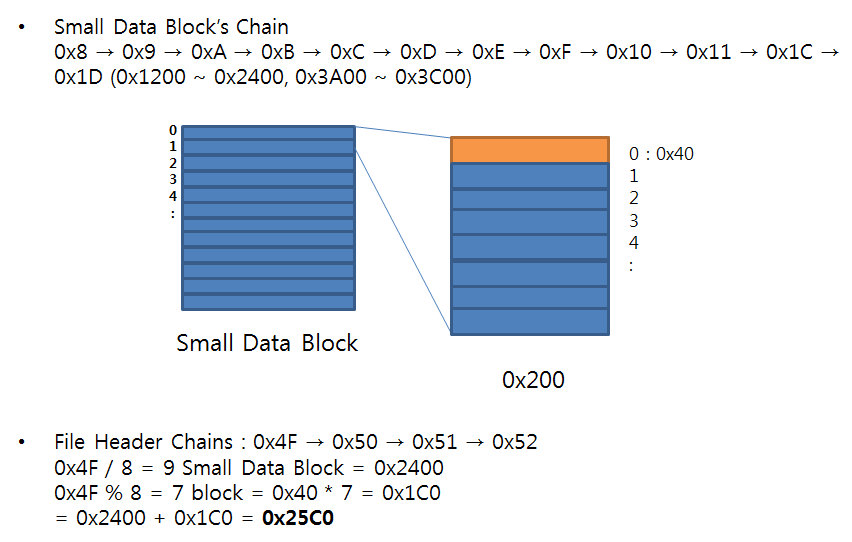
이들 블럭을 512(0x200) Byte 씩 읽어서 블록들을 모두 취합한 후 RootEntry 프로퍼티의 크기로 조절하면 RootEntry 프로퍼티의 데이터 내용이 된다. 이것이 바로 Small Data Block이다. 즉, SBAT에서 지시하는 블록 번호가 참조해야 될 영역이다.
이렇게 취합된 Small Data Block 영역을 64(0x40) Byte로 나누어 블록 번호를 부여한다. 블록 번호는 0부터 시작한다.
앞서 미리 작업을 한 FileHeader 프로퍼티가 차지하고 있는 Entry를 기준으로 해당 각 블록의 위치 정보를 표현하면 다음과 같다.
Entry 0x4F → Entry 0x50 → Entry 0x51 → Entry 0x52
단, 아래에 기술된 블록의 위치 값의 기준은 Small Data Block 영역에서 기준이다.
79블록(0x0x13C0) → 80블록(0x1400) → 81블록(0x1440) → 82블록(0x1480)
사실 프로그램으로 개발할 때 위 방식으로의 계산은 Small Data Block 영역을 기준으로 하고 있기 때문에 Small Data Block을 모두 완성을 해야 한다. 만약 Small Data Block 영역이 너무 크다면 메모리를 많이 차지하기 때문에 좋은 방법은 아니다.
따라서 메모리를 적게 차지하는 방법으로 바로 위치를 계산하는 방법을 택하게 된다. 예를 들면 FileHeader 프로퍼티는 79 블록부터 시작된다. 사실 FileHeader 프로퍼티는 SBAT를 참조하고 있으므로 한 개의 블록은 64(0x40) Byte를 차지한다. 그러므로 아래와 같이 계산을 하는 것이 간편하다.
- 79 블록 / 8(512 Byte에 64 Byte 크기의 블록은 8개로 구성) = 9
Small Data Block는 아래의 블록 정보에서 생성되었다.
8블록(0x0x1200) → 9블록(0x1400) → 10블록(0x1600) → 11블록(0x1800)
→ 12블록(0x1A00) → 13블록(0x1C00) → 14블록(0x1E00) → 15블록(0x2000)
→ 16블록(0x2200) → 17블록(0x2400) → 28블록(0x3A00) → 29블록(0x3C00)
따라서 9번째 블록 정보를 찾는다(최초의 블록은 0번째이다). 9번째 블록 정보는 17 블록이다. 즉, 해당 블록의 위치 정보는 0x2400이다.
- 79 블록 % 8 = 7
위치 정보인 0x2400에 작은 블록 정보은 7 블록 정보가 존재하므로 7 * 0x40 = 0x1C0이다. 최종적으로는 0x2400 + 0x1C0 = 0x25C0이 79 블록의 실제 위치가 된다. 지금까지 내용을 간단히 정리하면 아래와 같다.
아래 결과는 FileHeader 프로퍼티의 시작 영역인 79 블록(0x25C0)을 Hex 덤프한 것이다.
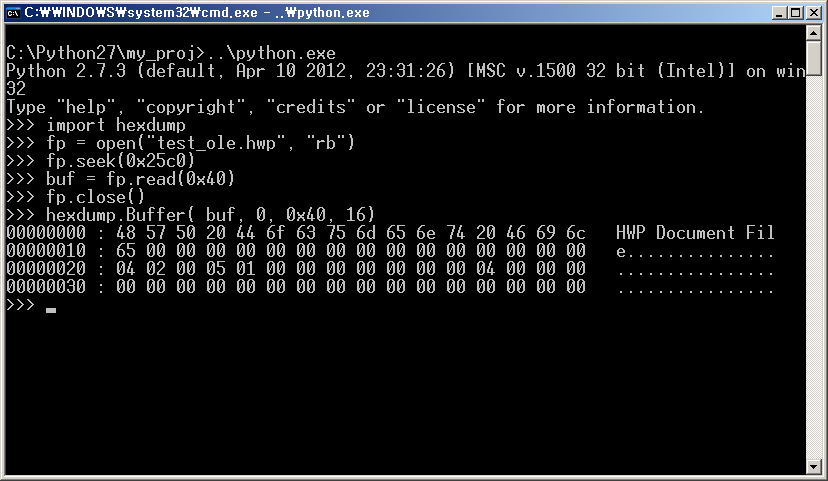
즉, FileHeader 프로퍼티의 데이터 내용은 시작은 HWP Document File 이라는 문자열로 시작하는 것을 확인할 수 있다.
실습
[소스 코드 : ]
[소스 코드 설명]
[실행 결과]
Update
- 2015-08-27 : 최초로 작성