
OLE 파일 포맷 (6) - Extra Big Block Allocation Table(XBBAT) Depot
지금까지 다루었던 test_ole.hwp 파일은 크기가 작은 파일에 속한다. 하지만, OLE 파일은 덩치가 큰 파일들이 얼마든지 존재할 수 있다. 예를 들어 파워포인트 파일을 생성하여 동영상을 임베딩하게 되면 그 크기는 엄청나게 커진다는 것을 알 수 있을 것이다. 사실 지금까지 다룬 OLE 파일 구조에서 하나를 빠트린 부분이 바로 이런 큰 파일을 핸들링하기 위한 Extra Big Block Allocation Table Depot 부분이다.
우선 예를 들기 위해 기존에 사용했던 test_ole.hwp 파일과 크기가 큰 OLE 파일의 이름을 test_big_ole.ppt 파일을 준비하였다.
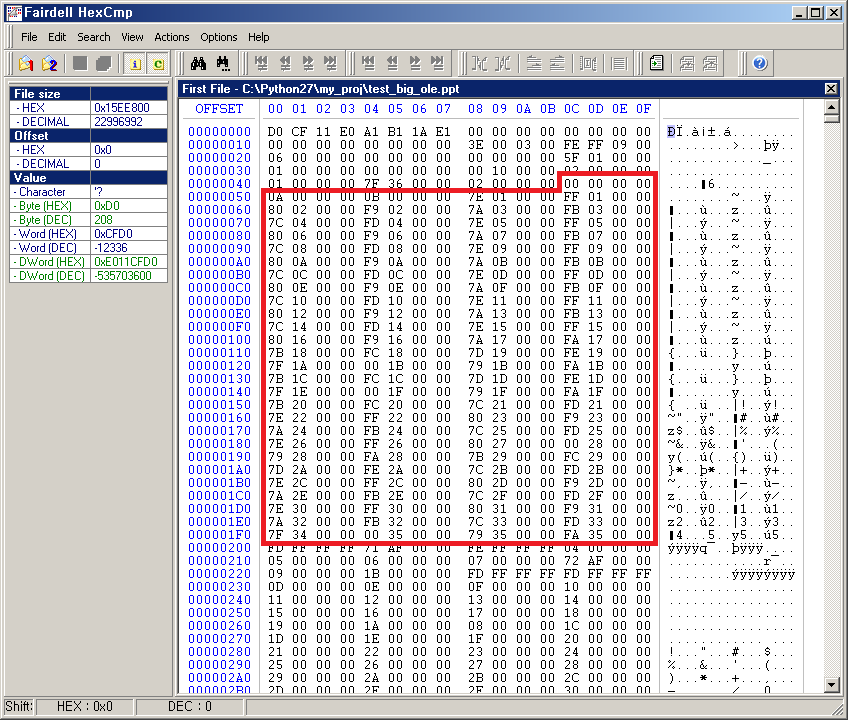
아래는 파일의 크기가 작은 OLE 파일(test_ole.hwp)과 큰 OLE 파일(test_big_ole.ppt) 두 개의 헤더 블록을 Hex 덤프한 것이다. 빨간 박스로 표시한 부분을 보면 크기가 작은 OLE 파일은 Array of Big Block Allocation Table Depot members 부분이 대체로 0xFFFFFFFF 값으로 채워진 반면 크기가 큰 OLE 파일은 BBAT를 가르키는 블록 번호들로 채워져 있다.
크기가 작은(약 512KB) OLE 파일의 헤더 블록
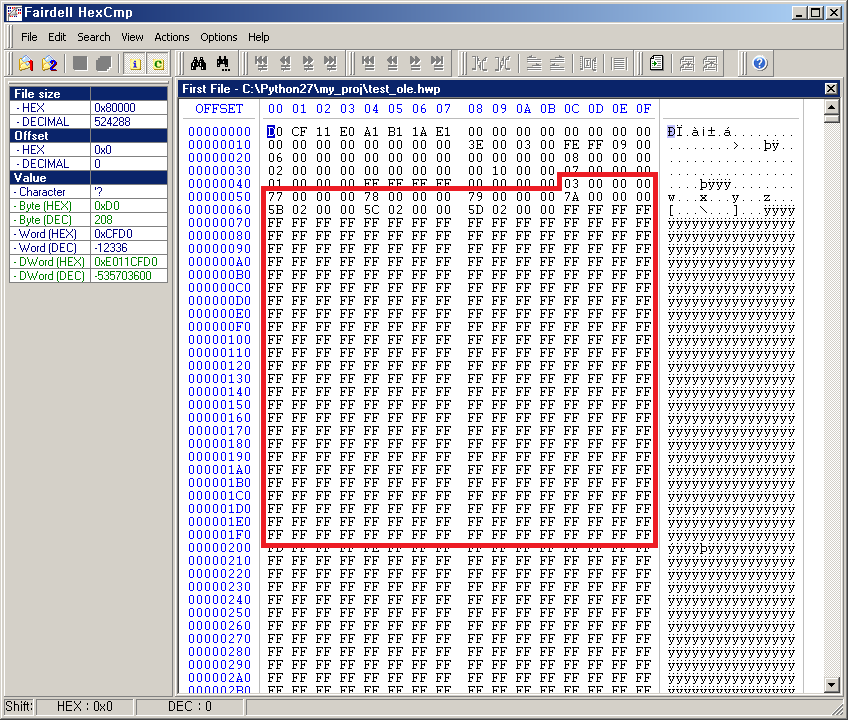
크기 큰(약 22MB) OLE 파일의 헤더 블록
OLE 파일의 헤더 블록에 존재하는 Array of Big Block Allocation Table Depot members에 들어갈 수 있는 최대 개수는 109개이다. 약 OLE 파일의 크기가 7MB를 넘어서게 되면 Array of Big Block Allocation Table Depot members 공간을 다 채우게 된다.
두 파일을 번갈아 가며 그 값을 비교하기 위해 기존에 사용하던 소스코드를 조금 변형해야 겠다.
[소스 코드 : test_readblock.py]
001 : # -*- coding:utf-8 -*-
002 : # Module : test_ole_block.py
003 :
004 : import ole
005 : import hexdump
006 : import sys
007 :
008 : #-----------------------------------------------------------
009 : # Test 코드
010 : # 사용법 :
011 : # test_ole_block.py [OLE 파일 명] [OLE 블럭번호] [출력 위치] [출력 크기]
012 : #-----------------------------------------------------------
013 : # 인자값 검사
014 : if len ( sys.argv ) != 5 :
015 : print "Input value error!"
016 : exit()
017 :
018 : # 특정 블럭을 읽어 buffer에 저장
019 : fp = open ( sys.argv[1], "rb" )
020 : Buffer = ole.ReadBlock ( fp, int(sys.argv[2]) )
021 : fp.close()
022 :
023 : # Buffer를 Hex 덤프
024 : hexdump.Buffer ( Buffer, int(sys.argv[3]), int(sys.argv[4]))
[소스 코드 설명]
- 4 ~ 6행 : 필요한 모듈을 import 한다.
- 13 ~ 16행 : 인자값을 검사한다. 만약 5개의 인자값이 입력되지 않을 경우 에러 처리를 하고 종료한다.
- 18 ~ 21행 : 주어진 OLE 파일을 열어 주어진 인자값을 통해 OLE의 특정 블럭을 한 블럭 읽는다.
- 23 ~ 24행 : 읽어들인 한 개의 블럭을 Hex 덤프로 출력한다. 이때 인자값으로 주어진 출력 위치, 출력 크기에 맞게 출력을 조절한다.
이제 각 파일의 차이점에 대해서 알아보도록 하자. 우선 각 파일의 Number of Big Block Allocation Table Depot 값을 살펴보면 아래와 같다.
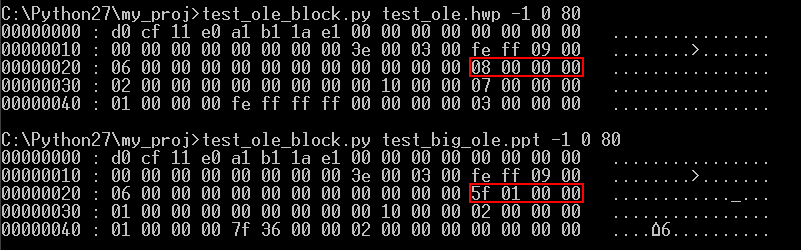
위쪽의 크기가 작은 test_ole.hwp 파일의 경우 BBAT가 8개인 반면 아래쪽의 크기가 큰 test_big_ole.ppt 파일은 BBAT의 개수가 351개다.
다음은 Start block of Extra BBAT Depot과 Number of Extra BBAT Depot을 살펴보면 아래와 같다.
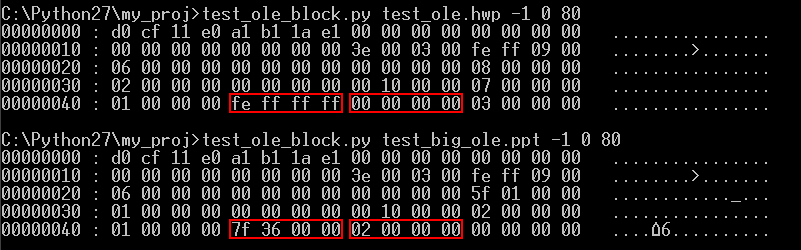
위쪽의 크기가 작은 test_ole.hwp 파일의 경우 Start block of Extra BBAT Depot은 0xFFFFFE으로 ‘없다‘는 의미를 가지며, Number of Extra BBAT Depot도 0을 나타내고 있다. 하지만, 아래쪽의 크기가 큰 test_big_ole.ppt 파일의 경우 Start block of Extra BBAT Depot이 존재하며, Number of Extra BBAT Depot도 2를 나태내고 있다. 즉, 헤더 블록에 존재하는 Array of Big Block Allocation Table Depot members 이외에도 2개가 더 있다는 의미이다.
따라서 아래의 그림처럼 작업을 해야 최종 BBAT를 완성할 수 있다.
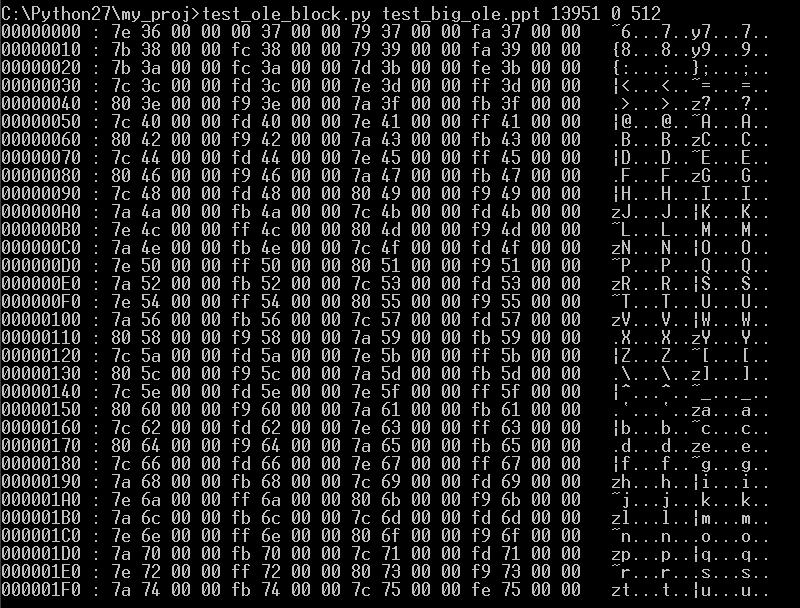
그렇다면, 첫 번째 Extra BBAT Depot의 블록을 Hex 덤프 해보자. 0x367F 블록은 10진수로 변환하면 13951 블록이다. 따라서 아래와 같은 결과를 얻을 수 있다.
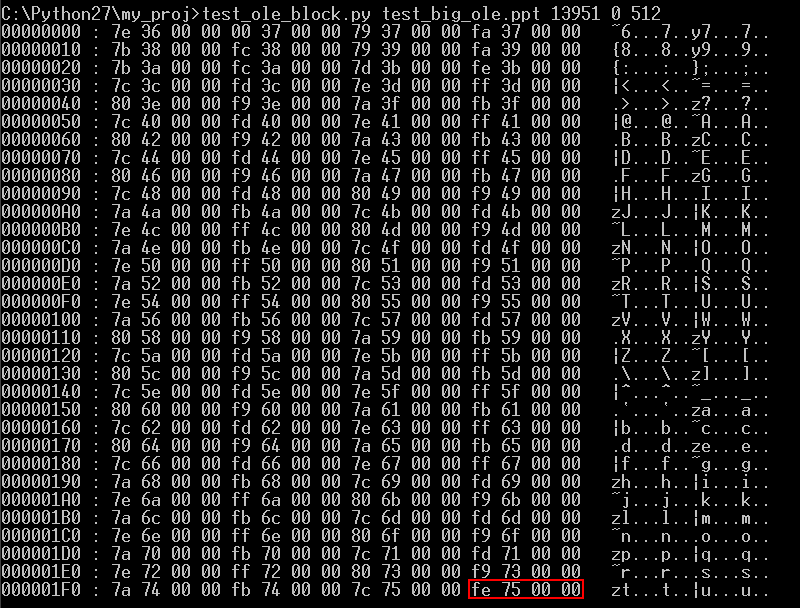
두 번째 Extra BBAT Depot은 어디에 있을까? Start block of Extra BBAT Depot 값이 13951(0x367F) 블록이니 BBAT의 Entry 13951을 보면 다음 위치가 있지 않을까? 답은 틀렸다. 왜냐하면 지금하고 있는 작업은 BBAT를 생성하는 것이다. 따라서 생성중인 BBAT를 참조한다는 것은 맞지 않다. 그렇기 때문에 Extra BBAT Depot의 경우 다음 블록에 대한 정보를 Extra BBAT Depot 블록의 마지막 4 Byte에 넣어두었다.
아래에 표시된 부분이 바로 다음 Extra BBAT Depot의 블록 번호이다.
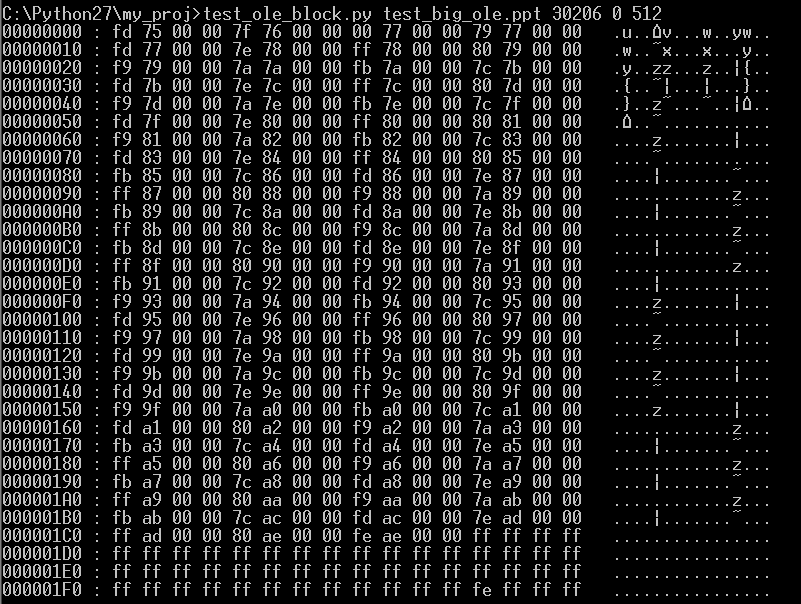
따라서 다음 Extra BBAT Depot의 블록 번호는 0x75FE 이며, 10진수로 변환하면 30206 이다. 아래는 30206 블록을 Hex 덤프한 결과이다.
지금까지 살펴본 것과 같이 Extra BBAT Depot 한 개의 블록에는 127개의 Extra BBAT 정보와 다음 Extra BBAT Depot 블록을 가르키는 위치 정보로 구성이 되어 있다. 따라서 최종 BBAT를 구성할 때에는 Extra BBAT Depot 블록에서 127개의 Extra BBAT 정보만을 취하고 한 개의 위치 정보 값은 Extra BBAT에서 배제해야 한다.
이제 Extra BBAT를 다루게 되면서 모든 OLE 파일 구조에 대한 접근이 가능해졌다.
실습
test_big_ole.ppt 파일의 모든 프로퍼티를 파일로 추출하는 프로그램을 개발해 보자. 대용량 파일임을 고려하여 Extra BBAT를 지원하도록 설계해야 한다.
[소스 코드 : ]
[소스 코드 설명]
[실행 결과]
Update
- 2015-08-27 : 최초로 작성